


Fine-Tuning vs RAG vs Prompting
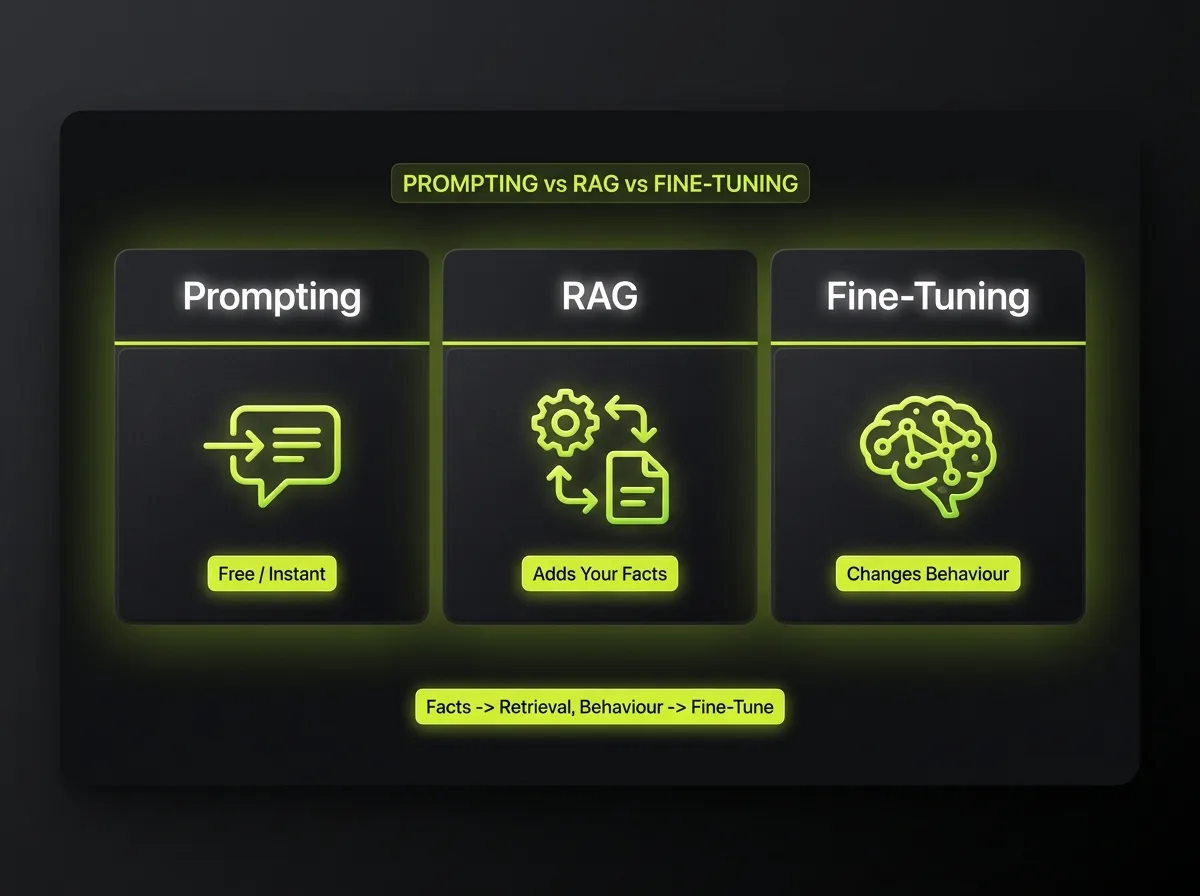
Most teams ask for fine-tuning when they actually need one of the cheaper two options, so this is the first decision we work through honestly. Prompting is changing what you tell the model, including giving it examples in the prompt; it is free, instant, and solves a surprising amount. Retrieval-augmented generation, or RAG, adds your own knowledge to the model at query time by fetching relevant documents and feeding them in as context. Fine-tuning, supervised fine-tuning specifically, actually adjusts the model's weights by training it on hundreds or thousands of your input-output examples. The rule we live by: if the problem is the model does not know your facts, that is a RAG problem, because facts belong in retrieval where you can update them instantly, not baked into weights you would have to retrain.
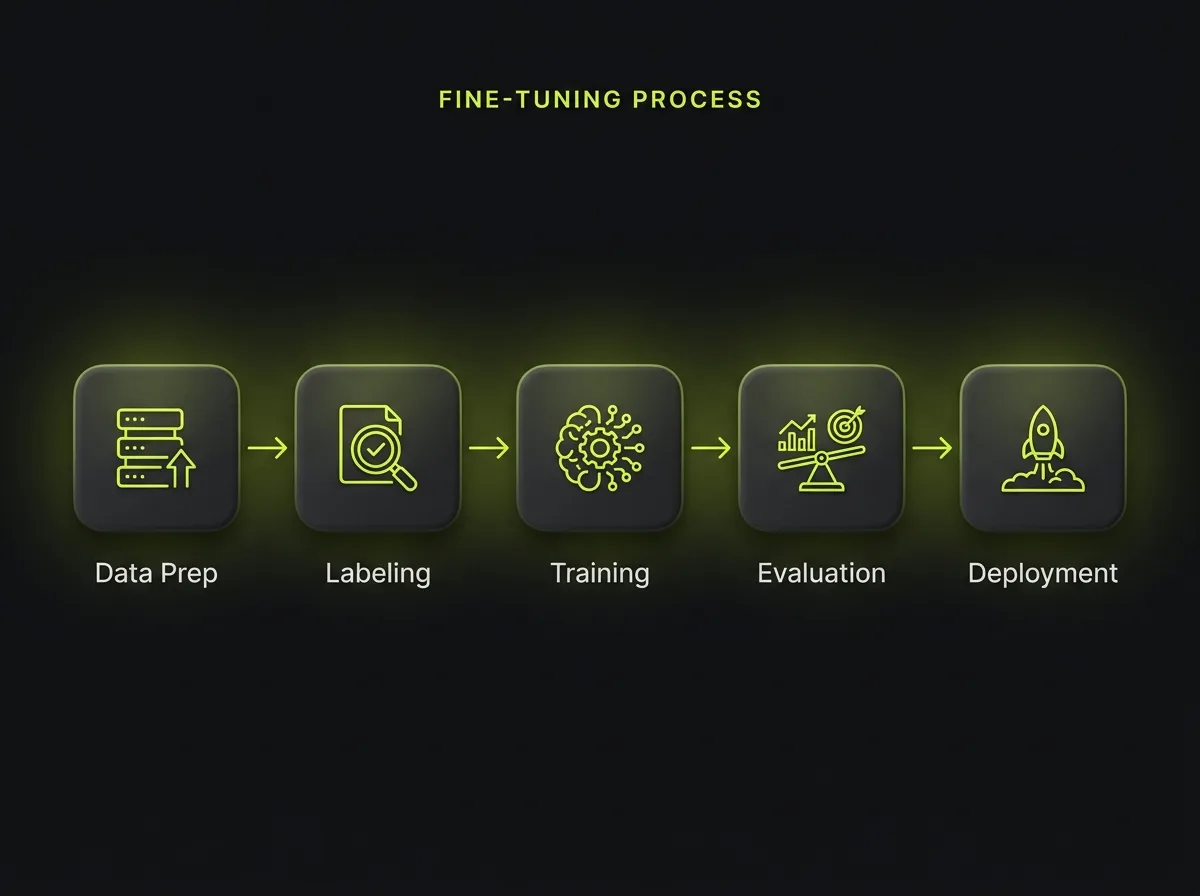
Fine-tuning earns its place when the problem is behaviour rather than knowledge: a consistent format, tone or style you cannot reliably get from prompting, a narrow classification task you want to be fast and cheap, or compressing a capability onto a smaller open-weight model like Llama or Mistral to cut inference cost at high volume. The trade-offs are concrete. Prompting and RAG are cheap and updatable but bounded by the base model's behaviour. Fine-tuning bends behaviour and can lower per-call cost, but it needs quality data, costs money to train, and goes stale as your needs change. Our standard path is prompting, then RAG, and only fine-tune with a measured reason, the same framework we apply across our custom AI tool development.